
Contributions to Exodus are welcomed! Please ensure that the code you're contributing fits with the Design Philosophy of Exodus. If you're making a significant modification or addition, it might be worthwhile making contact on the forums first to check if your changes might overlap or be affected by other upcoming changes. The basic steps for making a code submission are as follows:
Any code contributions to the Exodus project are greatly appreciated. This project can only meet its intended goals of supporting a wide variety of platforms through the contributions of others.
The easiest way to contribute code changes to Exodus is to "fork" the Exodus repository, and make the changes you want to make in that fork. When you're happy with the changes you've made, and you'd like them to be merged into the official repository, you submit a "pull request", and your changes can then be reviewed, and merged in once they pass the review. When you hear the word "fork", you may think that implies that you're breaking away from the Exodus project and starting your own independent project that will run forever into the future. This actually isn't how forks are intended to be used with hosted source repositories. The purpose of forks is to keep a relationship between the source repository and your fork of it, so that you can eventually merge the two together again through a pull request. Forks can be thought of as essentially being the same as "branches", but branches designed to work better with independent and disconnected programmers or programming groups.
Here are a few guidelines on how to make working with forks easier, and for your changes to have a better chance of being merged:
A Contributor License Agreement is something that's vital for open source development, and there is an increasing awareness of its importance today. A Contributor License Agreement, or CLA, is designed to protect open source projects, and the contributors to those projects, from possible legal consequences and dilemmas that can and do arise. Without a CLA in place, there are very real liabilities that can have major consequences for contributors and open source projects themselves. Many of these issues are rare, and require malicious intent from someone deliberately trying to harm a project, but there are real life examples of many of these issues arising.
When someone submits code to an open source project without a CLA, the code they submit remains their personal responsibility. When the code is shared or distributed in source or binary form, they remain personally responsible for their contribution. If the code is distributed under some form of license agreement, every contributor of code to that project is entering into a direct and individual agreement with every user of that code. This also means they are personally responsible for any legal ramifications of that code. If the code they have written infringes on any patents, or if any individual alleges that it has infringed on any patents, or if there is a dispute about breach of copyright, or any other form of legal claim of damage or misuse, a legal dispute can be directed at the licensor (the author) by the licensee (the user). This means if an organization or individual had cause to file a legal dispute, they could, and in fact must by law, direct that dispute to individual code contributors to that project. In the event those contributors lost a legal challenge, they would be personally responsible for any damages awarded as a result.
You may assume that when someone submits code changes to an open-source project, they've automatically given permission to the people maintaining that project to actually use the code they sent them, and integrate it in the main source repository, build a compiled program from it, modify it, and so on. Legally they haven't, unless that contributor made a formal statement to that effect. You may also assume that because someone contributes code to an open source project, the person who made the submission has given that project the right to use that code forever into the future. Legally, that also isn't the case unless they stated so. Without a CLA, 10 years after making a submission to a project, a contributor could decide he no longer wants his code to be included in the project, and formally demand it be removed. Legally it would be his right to do so. In this kind of case, his code contributions, and all derived works (things build from or using that code) must be stripped out of the code repository, and purged from its history. All releases of the software to include his code must be removed from distribution. Any sharing of that code as source or binary is no longer permitted. This could literally destroy open source projects if a significant former contributor turned against the project.
There is another liability for open source projects without a CLA, and that is, as described above, when the code is distributed in source or binary form, without a CLA it is actually each author entering an individual license agreement with each user. This also means that if there is a breach of the license agreement, it is the responsibility of each individual author to pursue legal action to enforce the license. Nobody else has the right to do this. Most contributors would not be willing to do this individually, and in the case of authors that are no longer involved in a project, or no longer contactable, this effectively gives anyone the ability to violate the license agreement for any code those authors have submitted without consequence, because nobody except the original authors can enforce the license.
The fundamental issue here is one of copyright law. Copyright law gives the original author of a work the rights to decide who is allowed to copy or alter their work, and the original author has the exclusive right to make those decisions. The original author also has the exclusive responsibility to ensure his work is used within the rights that he has granted to others. This works well where there is only single author for a work, but where an author is contributing their work as part of a larger work that is formed from the contributions of many others, it is essential that the group overseeing that larger work be granted some rights under copyright law. A Contributor License Agreement is the means by which a contributor to a project grants some rights and responsibilities for their contribution to the group managing that project. In any other place where authors publish their own work through some form of formal journal, paper, book, or similar media, they must agree to assign or grant some irrevocable rights to the publisher, or their submission will not be accepted. Open source software projects must have the same requirements if they are to protect themselves and their contributors legally.
The Contributor License Agreement that the Exodus project has adopted is the same license used by Apache and Google to govern contributions to their open source projects. It is unmodified except to reference the Exodus project where appropriate. This agreement in no way affects your rights to do whatever you want with the code you have written. What it does is ensure that once you've submitted code to this project, you can't change your mind about it later, nor are you legally responsible for what the project does with your code afterwards. It also ensures that the project is free to release your contributed code to other people as source and binary releases. Basically, it's formalizing exactly what you probably thought was already implied by submitting code changes to this project.
In order to clarify the intellectual property license granted with Contributions from any person or entity, the Exodus Open Source Project (the "Project") must have a Contributor License Grant ("Grant") on file that has been signed by each Contributor, indicating agreement to the license terms below. This license is for your protection as a Contributor as well as the protection of the Project and the Exodus Open Source Project Leads (the "Project Leads"); it does not change your rights to use your own Contributions for any other purpose.
You accept and agree to the following terms and conditions for Your present and future Contributions submitted to the Project. Except for the license granted herein to the Project Leads and recipients of software distributed by the Project Leads, You reserve all right, title, and interest in and to Your Contributions.
Definitions.
"You" (or "Your") shall mean the copyright owner or legal entity authorized by the copyright owner that is making this Grant. For legal entities, the entity making a Contribution and all other entities that control, are controlled by, or are under common control with that entity are considered to be a single Contributor. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "Contribution" shall mean any original work of authorship, including any modifications or additions to an existing work, that is intentionally submitted by You to the Project Leads for inclusion in, or documentation of, any of the products managed or maintained by the Project Leads (the "Work"). For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Project Leads or their representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Project Leads for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by You as "Not a Contribution."
Grant of Copyright License. Subject to the terms and conditions of this Grant, You hereby grant to the Project Leads and to recipients of software distributed by the Project Leads a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare derivative works of, publicly display, publicly perform, sublicense, and distribute Your Contributions and such derivative works.
Grant of Patent License. Subject to the terms and conditions of this Grant, You hereby grant to the Project Leads and to recipients of software distributed by the Project Leads a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by You that are necessarily infringed by Your Contribution(s) alone or by combination of Your Contribution(s) with the Work to which such Contribution(s) was submitted. If any entity institutes patent litigation against You or any other entity (including a cross-claim or counterclaim in a lawsuit) alleging that your Contribution, or the Work to which you have contributed, constitutes direct or contributory patent infringement, then any patent licenses granted to that entity under this Grant for that Contribution or Work shall terminate as of the date such litigation is filed.
You represent that you are legally entitled to grant the above license. If your employer(s) has rights to intellectual property that you create that includes your Contributions, you represent that you have received permission to make Contributions on behalf of that employer, that your employer has waived such rights for your Contributions to the Project Leads, or that your employer has executed a separate Corporate Contributor License Grant with the Project Leads.
You represent that each of Your Contributions is Your original creation (see section 7 for submissions on behalf of others). You represent that Your Contribution submissions include complete details of any third-party license or other restriction (including, but not limited to, related patents and trademarks) of which you are personally aware and which are associated with any part of Your Contributions.
You are not expected to provide support for Your Contributions, except to the extent You desire to provide support. You may provide support for free, for a fee, or not at all. Unless required by applicable law or agreed to in writing, You provide Your Contributions on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON- INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE.
Should You wish to submit work that is not Your original creation, You may submit it to the Project Leads separately from any Contribution, identifying the complete details of its source and of any license or other restriction (including, but not limited to, related patents, trademarks, and license agreements) of which you are personally aware, and conspicuously marking the work as "Submitted on behalf of a third-party: [named here]".
You agree to notify the Project Leads of any facts or circumstances of which you become aware that would make these representations inaccurate in any respect.
The current release of Exodus is version 2.1. Download links for all required files are provided below.
Exodus requires the Microsoft Visual C++ runtime to be installed before it can run. If you're not certain you already have this installed, please download and install the runtime before attempting to run Exodus. If you get an error about a missing dll when attempting to launch, the runtime is probably not installed correctly.
Please note that although Exodus is currently setup to load an emulated Sega Mega Drive system by default, this will change in the future as support is added for more systems.
| Visual C++ 2017 x64 Runtime | Download |
| Exodus 2.1 | Download |
The compilation process for Exodus has been designed to be as simple as possible. There are however a few steps involved in getting up and running the first time, especially if you don't currently have the required tools installed. The following article will walk you through the steps for obtaining the source code for Exodus, and compiling it on your own computer.
Please note that Windows is the only supported platform for compilation. Feel free to experiment with other platforms if you wish, but no support is currently provided for this.
The sourcecode for Exodus is hosted with GitHub at https://github.com/RogerSanders/Exodus. You have two different options for downloading it to your computer: the quick and dirty way that'll get you the code in one step, but without any of the code revision history, and make it hard to pull in updates or contribute changes, or the slightly longer but proper way. I'd strongly recommend the latter. If you really just want the latest files with no fuss, the quick and dirty way is to grab the latest zip snapshot of the current development mainline from the GitHub repo.
As for the proper way, you need to have a Git client installed, and clone the repository from GitHub. There are a variety of ways to perform this task that vary between platforms, and a step by step guide is not provided here at this time. Refer to external instructions around performing a clone operation from a GitHub repo for your platform/tool of choice.
Exodus currently uses Visual Studio 2013 as its development environment. Theoretically other IDE's could be used, as long as support exists for compiling MSBuild projects, but the only officially supported IDE is Visual Studio 2013. With the recently released Visual Studio 2013 Community Edition (note: This is different from the previous Visual Studio 2013 Express Edition), you get effectively the same IDE as Visual Studio 2013 Professional, but it's free for private and open-source development. If you don't have a license for a commercial version of Visual Studio 2013, I recommend using the Community Edition.
To setup your development environment, do the following:
There are a few third party libraries that are currently required in order to build the Exodus repository. In order to obtain the required third party libraries, navigate to the "Third" directory in your local copy of the Exodus repository, and download the following files into the subdirectories that exist in that folder.
For each compressed file you've downloaded, you now need to extract each one directly into the folder it's in. IE, if the archive name was "SomeArchive.zip", and it contained a compressed folder called "SomeFolder", after you extract, you should have SomeFolder sitting in the same directory as SomeArchive.zip. (Note: Catch and htmlhelp are exceptions to this rule. Catch must appear in a subdirectory called "Catch", and htmlhelp must appear in a subdirectory called "htmlhelp".). Ensure that you fully extract ".tar.gz" files. You need to extract the contents of the .tar file within the .gz file too.
With your development environment setup, you're ready to compile Exodus. This can be done on the command line with MSBuild, but the easiest way is within Visual Studio. To compile Exodus, do the following.
Note that you can compile individual plugins under the "Debug" configuration and leave everything else as a release build. This is usually the way you'll want to work if you're developing a plugin. A full debug build runs very slowly, so you would generally compile just the individual components you want as debug, such as one or two plugins, and possibly the system itself, while leaving unrelated plugins as release builds.
Official release builds of Exodus are given a speed boost through the use of Profile Guided Optimization. This technique involves instrumenting the code during compilation, and manually running the program with that instrumentation through a series of tasks, to gather information about what areas of the code are actually bottlenecks and runtime, then feeding that information back into the linker so that it can do a smarter optimization step. This has shown to increase average performance in Exodus by a modest 15% over a standard release build. If you do a normal build of Exodus on your local machine however, this optimization will not have been applied, so you can expect to see around a 15% performance degradation compared to the official release builds. If you want to optimize your own builds, you can do the following:
As you can see, this is a fairly manual process, and takes some time to run through. I wouldn't recommend trying to instrument everything at once, because the performance will be heavily degraded and the performance profile of the emulation cores will change due to bottlenecks in the system and other cores, which will affect the usefulness of the profile data. The selection of the actual test runs is important too. If you're instrumenting a graphics core, you need to run a program which uses the features of that core, so that the various code paths can be explored and profiled at runtime. You should ideally only instrument individual assemblies, or small batches of assemblies, together in the same run. This allows you to make shorter, more focused test runs, and produces a better performance profile.
The Exodus SDK support documentation is build from XML documentation files within the repository itself. To build it yourself locally, do the following:
The created documentation files will be in the "Documentation" folder in the root of the Exodus repository
To compile the unit test projects for Exodus (only one right now), do the following:
This page provides support documentation for Exodus. No user documentation is currently available, but preliminary developer documentation is available for the Exodus API. At this time, the documentation is very incomplete, and many major sections still need to be written. This documentation will receive continual updates over the coming months, after which changes should become more stable, and mostly be associated with new changes in the API.
The Exodus SDK documentation is currently available in three formats. This documentation is current as of the 29th of April 2015.
Exodus is a software program designed to allow real physical hardware to be emulated in software. This is not a revolutionary idea. There are many other emulators out there for a wide variety of tasks and systems. What makes Exodus a little different is what goals it tries to achieve, what it does that other emulators do not, and what it doesn't do that other emulators do. More detail is given about the goals of Exodus in the "Design Philosophy" section. In this section, you'll get a quick overview of what makes Exodus different.
So, what does make Exodus different from other emulators? There are a few key points:
More detail about each of these items will be given below.
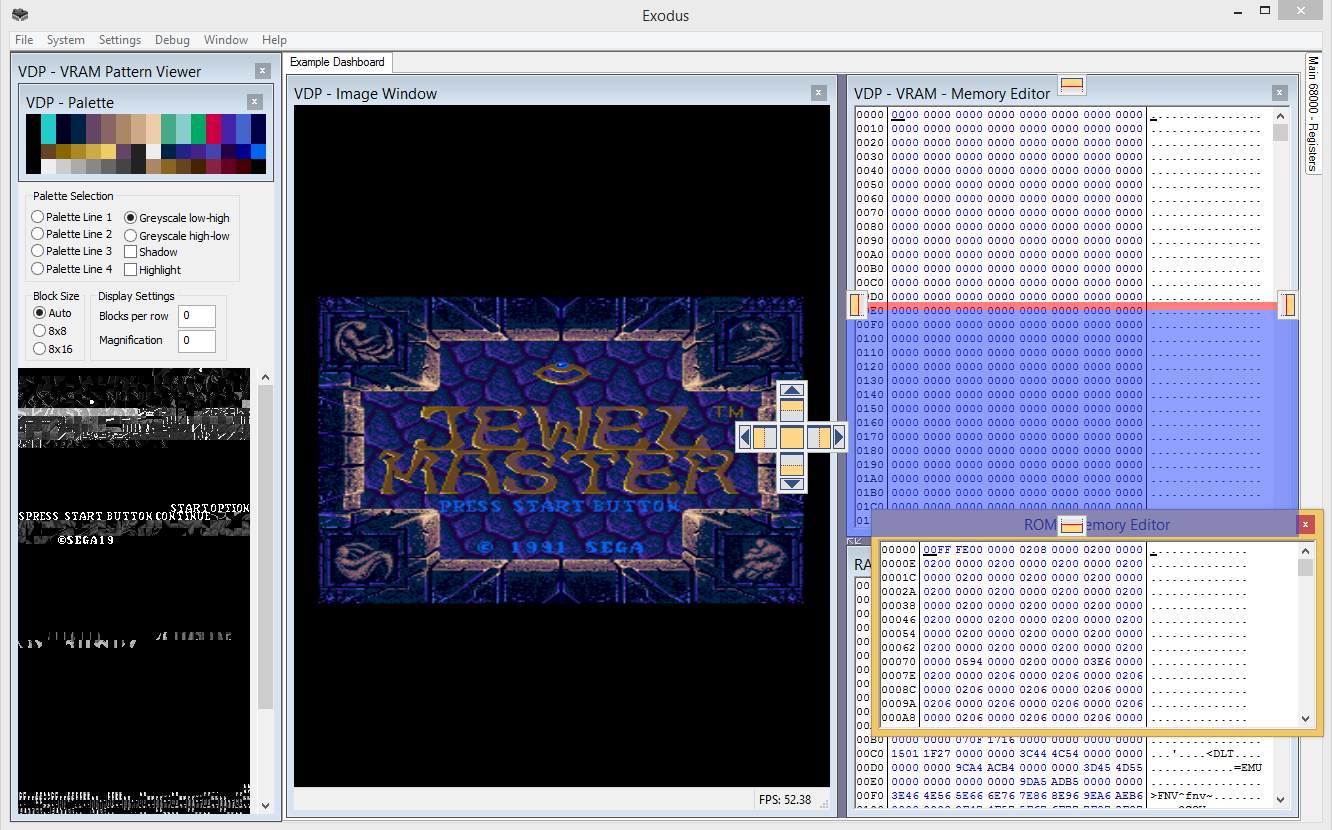
The first and most significant thing to understand about Exodus, is that it is not actually an emulator. Exodus is a generic emulation platform, which allows systems to be assembled from individual components at runtime. Plugins are used to add actual emulation support for real devices. A device may be an individual discrete component, such as a processor, sound, or video chip. This plugin model itself isn't as interesting as how Exodus builds systems from these devices. With Exodus, nothing that makes up a "system" is hardcoded. Exodus uses XML files, called modules, to build an actual system from a set of discrete components. The current system is simply defined as the current set of loaded modules, and any selected settings for those modules.
Perhaps more significantly than the plugin model itself, Exodus completely handles all the communication and interaction between each device. Exodus emulates the idea of the "system bus", and supports mapping devices in almost any way imaginable. Devices themselves can be written to simply emulate themselves in isolation, without knowing or caring about the system they are used in, or how they are physically connected to that system. When devices are emulated in this manner, they are inherently reusable in any system, under any situation in which the real device could be placed. This means that you only have to emulate one device, once, and there are no system-specific hacks that have to be applied in order to make that device work in a given system. Support can be added for new systems simply by writing an XML file to describe the physical devices in that system and the connection between those devices, and loading the file in the Exodus platform, provided emulation cores exist for all the required devices.
With this plugin model, and the XML-based method of defining system components, Exodus is probably the most generic, flexible, and scalable emulation platform ever written. The long-term goal of Exodus is to provide support for as many systems as possible, even to rival other projects such as MESS and MAME. The project goals, architecture, and design philosophy are setup to attempt to make this emulator easier to maintain and more flexible over time than other large-scale emulation projects however, as well as providing several key advantages they currently do not offer.
So, apart from this modular architecture, what's interesting about Exodus? The most important thing is accuracy, in particular, timing accuracy. Most emulators are extremely inaccurate when it comes to timing. The reason for that is that there's often a huge performance tradeoff involved. In a real system, you might have half a dozen or more discrete devices all doing things at the same time. Each device might run at its own rate with its own performance characteristics. In a real system, those devices are not completely isolated, that wouldn't be a very useful system, those devices need to interact. When you're emulating that system, how do you ensure that every single device access occurs in the correct order though? The simple fact is, most emulators do not. Most emulators aim for a certain degree of timing accuracy, which is usually just enough to emulate some particular set of existing programs that run on that platform, and that's as accurate as they get. Timing related bugs often become the biggest roadblock to increasing emulation accuracy as an emulator advances, and increasingly become more and more difficult to solve. So, how do you solve timing problems with 100% accuracy? Well, the first, most obvious way, is to run every device in what's called "lock-step". This is simply to advance every device in the system one by one, advancing each device by a single "step", ensuring that no device gets ahead of another. This works with 100% reliability. It's also very, very, very slow. The biggest problem this approach has is that you reduce your emulator to a single-threaded model, because everything always has to wait for everything else, so you can't really do anything in parallel. Since we now live in the age of parallel computing, this effectively cripples the performance of your emulator now and into the future. That leads into the next topic.
Exodus was built from the ground up to solve the unsolvable timing problems, and has a unique approach to timing accuracy. It adopts what I call the optimistic execution model. This idea isn't new either. The concept is simple, and it goes something like this: "Most of the time, a timing problem is not going to occur. Given that assumption, I want to execute my devices unsynchronized for as long as possible. If something ends up happening in the wrong order, I want to roll back to the previous point, and repeat the operation, this time with fore-knowledge about the timing requirements". This is the execution model Exodus uses. By executing in parallel for as long as possible, we can make use of multiple cores. The idea of state rollback is implemented as a core part of the platform itself, and is heavily optimized to be as fast as possible where a rollback is not required. Devices can assist the emulation by giving advance notice about significant events, such as interrupt generation, which are likely to affect other devices. System XML definitions can also give additional timing hints, such as forcing particular devices to always remain behind the current execution point of other devices. A combination of these techniques allows Exodus to achieve 100% timing accuracy, while making effective use of multiple cores to execute devices in parallel for as long as possible.
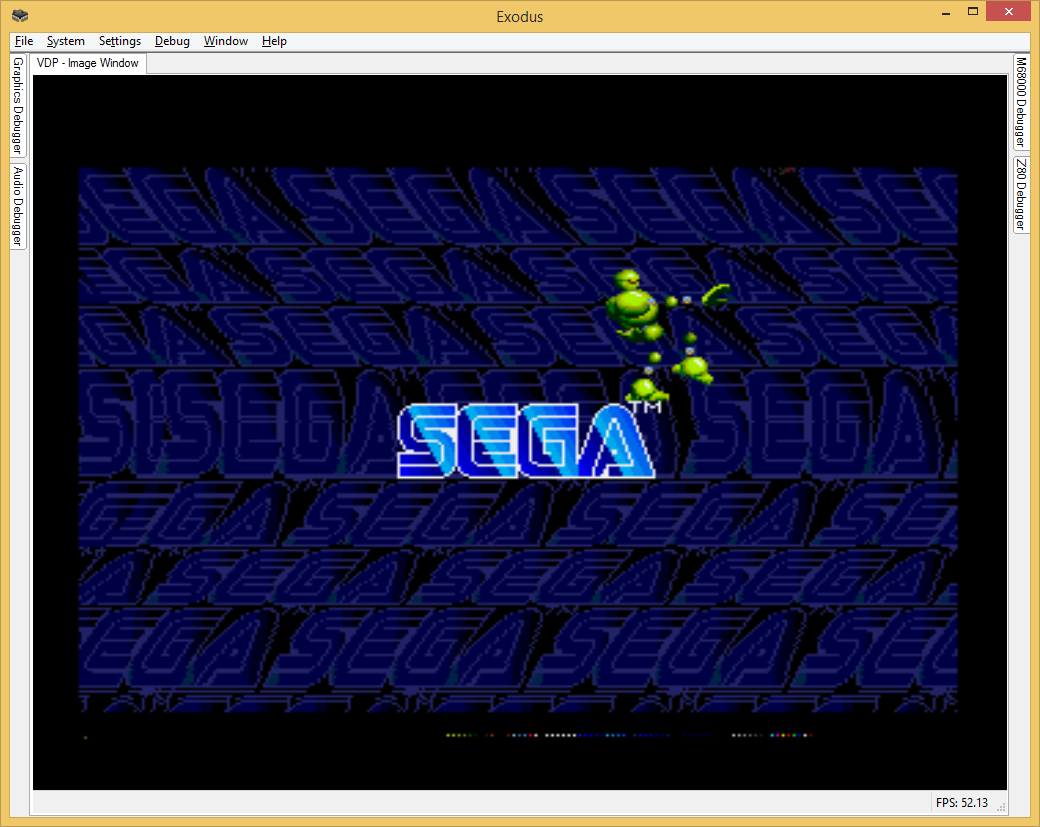
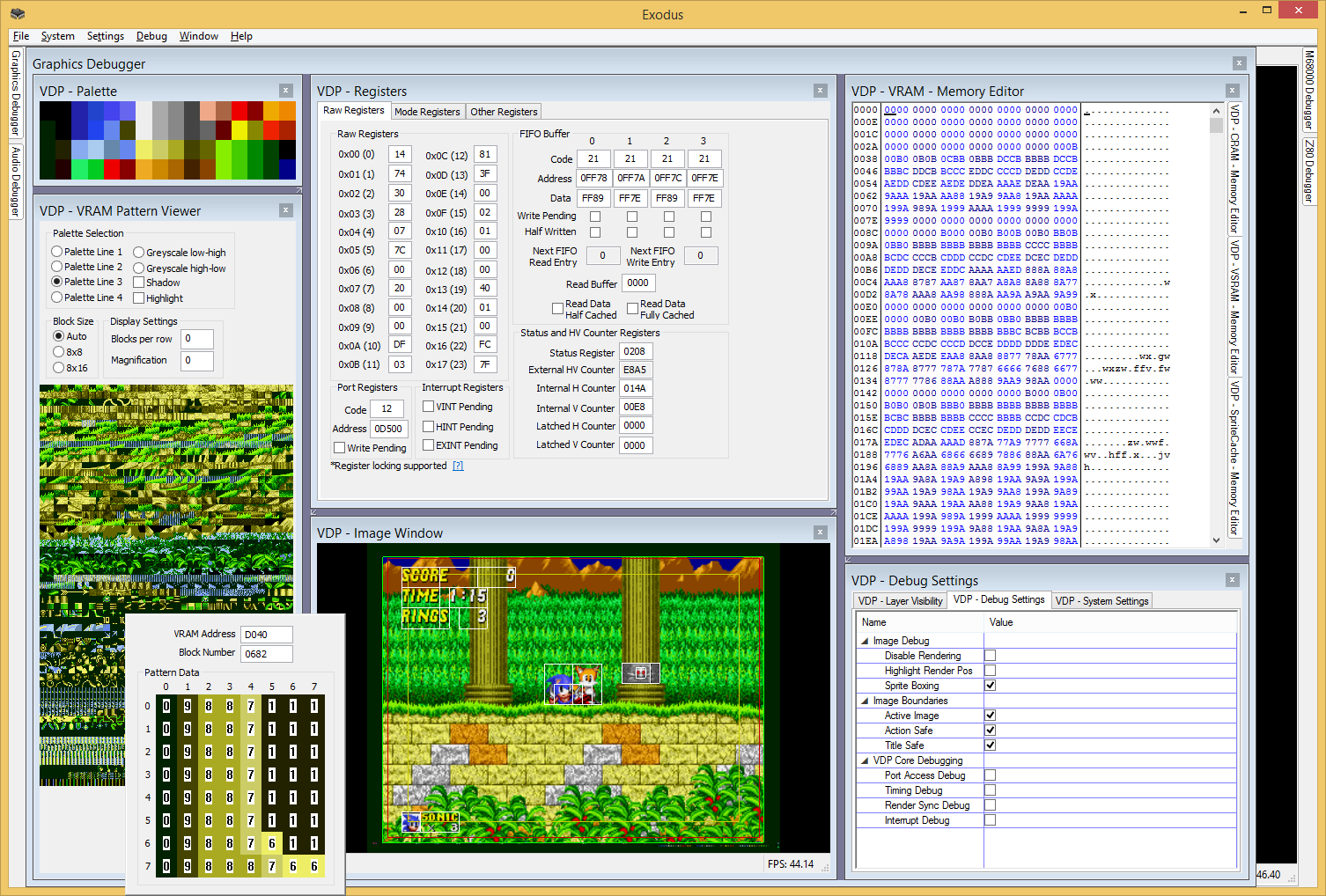
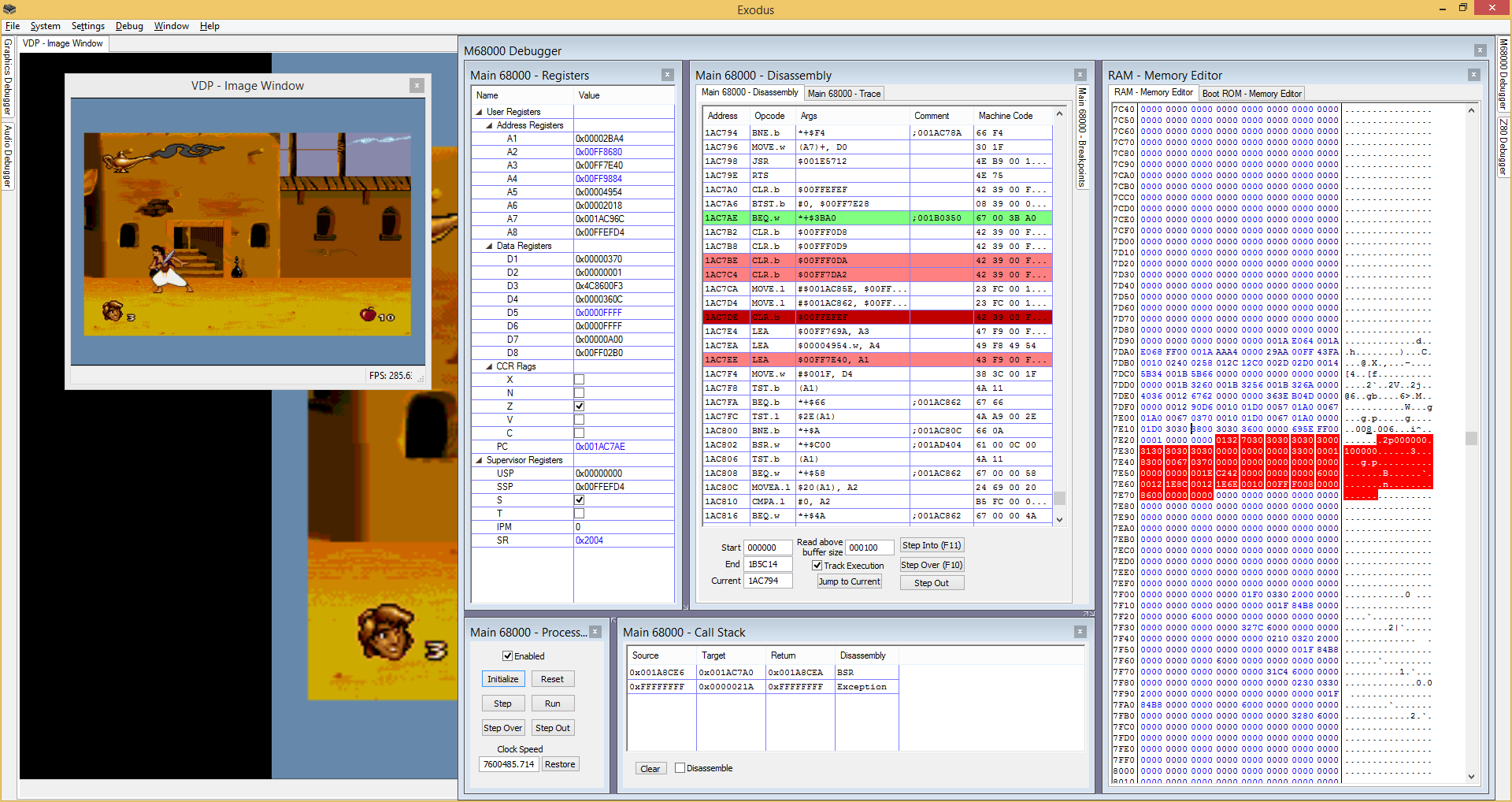
Another key point that makes Exodus different is simply what kind of users it targets. Exodus is not designed to allow you to play commercial games for mainstream systems. That may be a side-effect of what it does, but that is not its focus. There are many other emulators out there for a large number of systems. If you simply want to play games, one of those may be more suitable. Exodus is aimed at users who have a technical interest in a particular platform. A large number of debugging and diagnostic features are provided to assist in better understanding the internals of the hardware, and to assist in debugging problems, and developing code, where it may be difficult to gather information on the real hardware. To this end, Exodus has a strong focus on accuracy in all areas, with the goal that any given piece of code will behave exactly the same way in Exodus as it would on the real hardware. Debugging features are exposed to provide as much transparency as possible, so that at any given point, it can be understood what state each device is in, and to allow that state to be modified in real time through the debugger.
These points summarise the main things that make Exodus a little different from other projects. Hopefully this is enough to spark your interest. For more detailed information about the design of Exodus, as well as the current level of support and future plans of Exodus, please refer to other sections of this website.
A very specific philosophy governs this project. It is this philosophy that has shaped what Exodus has become thus far, and will continue to shape what it will become in the future. That philosophy can be broken down into the following key ideas:
A system is simply the combination of a set of discrete components. A Motorola 68000 chip in a Mega Drive is the same as a 68000 in an Amiga, an arcade system, etc. One core should exist for a given device, which emulates all the features of that device, so that the device can then be used in any system, without it being aware of any external details of the system that uses it. Each core should serve to make its emulation accurate and "feature complete", whether a particular feature or level of accuracy is required in any particular target system or not.
A good, clean architecture for a core is critical to ensure readability of the code, which directly affects how maintainable that core will be, and also how well it serves to document the device it emulates. All cores must be free from assembly code. This is critical for portability and future preservation of the core. In addition, all cores should make use of object and class structures where appropriate, and the code itself should be well written and structured.
Using less lines doesn't necessarily make your code better. You might be able to sum up a complex operation on one line using 10 bit shifts, half a dozen AND operators, and a few OR's. Consider carefully first if the resulting code is the cleanest, most readable way to express that operation. In most cases, a cleaner way exists. Use the "Data" class where appropriate, rather than directly performing bit manipulation. Avoid "magic numbers". Where constants exist, define them all in one place, then refer to them by name in code. This not only serves to make code more readable, it also helps to avoid bugs when writing code, especially when performing bit manipulation.
All cores should serve as a form of documentation on the device they emulate. To this end, the code must be well structured, readable, and extremely well commented. Cores need to be maintainable by future developers, not just the original author. Leave a 500 line comment if that's what you need to explain what something is doing. Where you use an external source of information to implement something, add it to the list of references for the project, so that other people can see why something is done a particular way. Someone should be able to understand everything they need to know about how your core works by reading through the code itself and the list of references. If they can't, you're missing a reference or a comment.
Every core should be as accurate as possible, and honestly report on its accuracy. If there is any point at which the real behaviour of the device is unclear, or where the core doesn't emulate a behaviour of the real device, it should be documented, so the limitations of a given core can be well understood to others, not just the original developer. Any "hacks", where something is written in a way that is known to be incorrect, just to get the correct apparent result in a given situation, should be avoided at all costs. These kind of hacks only serve to hide underlying problems, and make them harder to detect and debug later on. They ultimately hurt the goals of emulation and preservation rather than helping them.
Accurate emulation of timing is critical in a lot of systems. All cores should emulate the timing of the original hardware as much as is possible, in any case where that timing information can be observed by an external device. Cases where timing is known to not be respected, or where correct timing information is simply unknown, should be clearly documented.
It should be a goal of every emulation core to expose as many debugging features to the user as possible. Not only does this open the emulation platform up to people wanting to do development or testing, it also greatly assists in debugging the emulator itself, improving existing emulation cores, and developing new cores.
Performance is important, but only in as much as it does not infringe on good architecture, readable code, generic implementation, or accuracy. Computers get faster. Compilers get better. Inefficient code can be optimized later. Ultimately, slow cores will run full speed one day. On the other hand, unmaintainable cores will languish and die, no matter how fast they are. We're trying to preserve systems for the coming decades, not the next 2 years. We need to write cores that will stand the test of time.
If you understand the above philosophy, you will understand why Exodus has been designed the way it has, and what sets it apart from other emulators.




If you wish to make a donation to show your appreciation for this project, you can do so here. Your donation may go towards the hosting costs of the website, or equipment or reference hardware to assist in the development of Exodus. It may also go towards a bunch of flowers for my beautiful wife, to say thanks for your support and patience all those nights I stayed up late working on this project.